Карта памяти
Процессор содержит шинную матрицу, которая занимается арбитражем процессорного ядра и вспомогательного Отладочного порта (Debug Access Port (DAP) в моменты доступа к памяти как для внешней подсистемы памяти, так и для внутреннего системного пространства System Control Space (SCS) и компнентов отладки.
Приоритет всегда отдаётся процессорному ядру для гарантии того, что любые отладочные воздействия изолированы в их влиянии. Для системы с нулевым временем ожидания все отладочные воздействия к памяти, SCS и отладочным ресурсам всегда полностью прозрачны и не оказывают влияния на работу системы.
Карта памяти процессора Cortex-M3®:
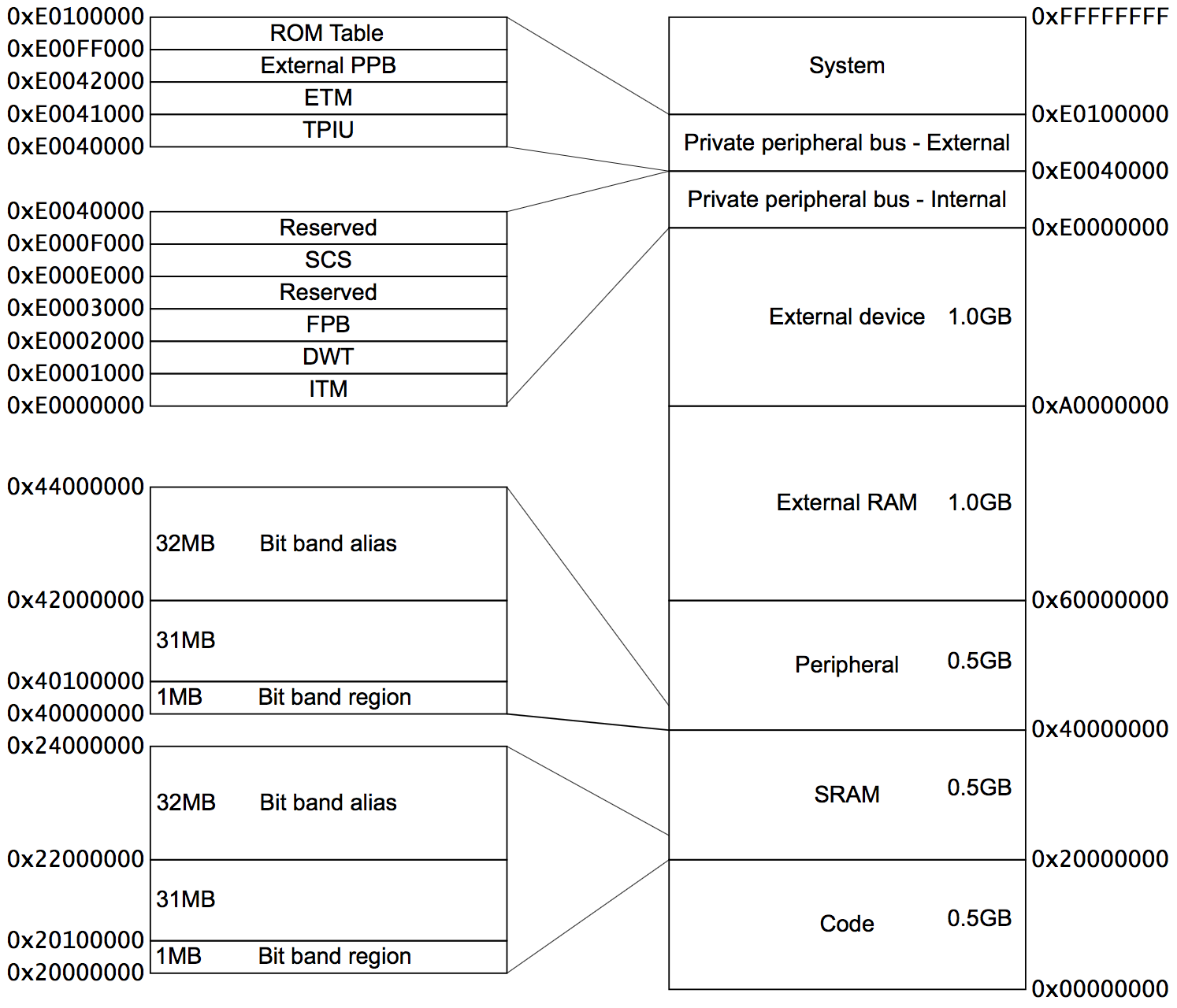
Рисунок 3-1. Карта памяти процессора
Некоторые процессорные интерфейсы перемещаются в различные регионы в рамках карты памяти:
- Code
- Процессор осуществляет загрузку инструкций через шину ICode. Данные загружаются через шину DCode.
- SRAM
- И инструкции и данные загружаются через системную шину.
- SRAM bit-band
- Это регион памяти ссылок. Доставляемые данные являются ссылками, инструкции — не ссылки.
- Peripherial
- И инструкции и данные загружаются через системную шину.
- Peripheral bit-band
- Также специальный регион ссылок. Данные передаются аналогично SRAM bit-band.
- External RAM
- Работает аналогично SRAM и Peripherial
- External Device
- Регион памяти внешних и внутренних частных периферийных шин (Private Peripheral Bus (PPB). Этот регион является неисполняемым Execute Never (XN), другими словами, инструкции не могут исполняться из этого адресного пространства. Это явно запрещено и MPU, если присутствует в системе, не имеет возможности это изменять.
- System
- Это сегмент памяти, выделенный под использование определяемой производителем периферии. Этот регион также является неисполняемым (XN) и инструкции, в этой связи, не могут выгружаться отсюда. MPU (если присутствует) не может изменить эту установку.
Если у вас есть дополнительные вопросы по модели памяти, смотрите в документ ARMv7-M Architecture Reference Manual (раздел A3).
К настоящему моменту существует только один способ получить ARMv7-M Architecture Reference Manual: зарегистрироваться на http://arm.com и скачать документ по названию, указав причину по которой вы интересуетесь этой информацией.
По очевидным причинам мы не имеем права распространять этот документ в качестве вложения.
Однако всем, кто интересуется работой процессора ARMv7-M следует ознакомиться с этим документом.
Private peripheral bus
Внутренняя Private Peripherial Bus (PPB) предоставляет доступ к:
- Instrumentation Trace Macrocell (ITM)
- Data Watchpoint and Trace (DWT)
- Flashpatch and Breakpoint (FPB)
- System Control Space (SCS), включая модуль защиты памяти (Memory Protection Unit (MPU) и комбнинируемый векторный контроллер прерываний (Nested Vectored Interrupt Controller (NVIC).
Внешняя PPB предоставляет доступ к:
- Trace Point Interface Unit (TPIU)
- Embedded Trace Macrocell (ETM)
- ROM
- специфичных для реализации картах памяти PPB.
Невыровненный доступ пересекающий границу региона
Микропроцессор Cortex-M3® поддерживает механизм невыровненного доступа ARMv7 и всегда исполняется как операция невыровненного доступа. На самом деле такие операции всегда конвертируются в две илли больше операции выровненного доступа на шинах DCode и System.
Все операции внешнего доступа у Cortex-M3 всегда выровненные операции.
Невыровненный доступ доступен только для единичных операций LDR,STR. Двойная загрузка/выгрузка всегда поддерживает выровненный по размеру слова доступ и не разрешает другие типы выравнивания и даже генерирует ошибку если подобная попытка была предпринята.
Невыровненный доступ, который пересекает границы карты памяти является архитектурно непредсказуемым. В зависимости от типа пересекаемой границы поведение процессора отличается. Например:
- DCode осуществляет “заворачивание” внутри региона. К примеру, невыровненный доступ к половине слова пытается получить доступ по адресу
0x1FFFFFFF. Он будет сконвертирован DCode шиной в байтовый доступ к адресу0x1FFFFFFFследующий за байтовым доступом к0x00000000. - Системный доступ который пересекает границу пространства PPB не будет завёрнут, а напротив приведёт к некорректному доступу. Например, невыровненный доступ последнего байта полуслова пространства System (
0xDFFFFFFF) будет сконвертирован интерфейсом System в байтовый доступ0xE0000000. Как говорилось выше, адрес0xE0000000не является корректным для шины System. - Аналогично с предыдущим пунктом, пересечение границы Code не заворачивается внутри пространства System. Так, невыровненный доступ последнего байта полуслова пространства System (
0xFFFFFFFF) будет сконвертирован интерфейсом System в байтовый доступ0x00000000. Как говорилось выше, адрес0x00000000не является корректным для шины System. - В пространстве PPB невыровненный доступ не поддерживается. В связи с этим не существует и проблемы пересеченя границы.
Невыровненный доступ, который может пересечь границу bit-band также является системно непредсказуемым. Процессор выполнит bit-band операцию, но эта операция не будет являться результатом bit-band операции. Например, невыровненный доступ полслова по адресу 0x21FFFFFF исполняется как байтовый доступ к 0x21FFFFFF следующий за байтовым доступом к 0x22000000 (первый байт bit-band ссылки).
Невыровненные загрузки, котоыре соответствуют литеральному компаратору в FPB не переназначаются. FPB переназзначает только выровненные адреса.
| Временные параметры Load/Store | Режимы работы |